Druid 大数据实时处理的分布式开源系统
在当今数据驱动的时代,企业面临着处理海量实时数据的巨大挑战。Apache Druid作为一个开源的分布式数据处理系统,应运而生,专为快速查询和分析大规模流式数据而设计。它结合了数据仓库、时间序列数据库和搜索系统的优势,为实时监控、事件驱动分析、运营智能等场景提供了强大的支持。
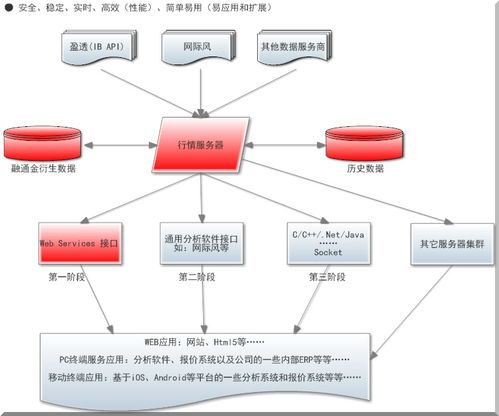
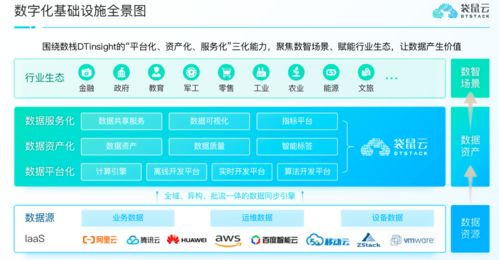
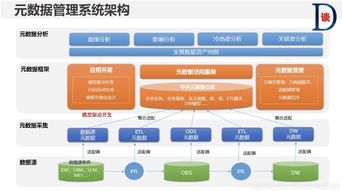
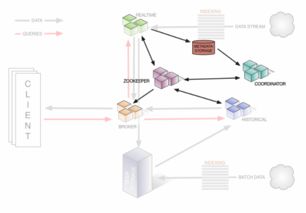
Druid的核心架构采用了分布式、可扩展的设计。其系统主要由协调节点、数据节点、查询节点和历史节点等组件构成,各司其职,协同工作。协调节点负责数据分片的管理和任务调度;数据节点处理实时数据摄取;历史节点存储和查询历史数据;查询节点则接收并处理来自客户端的查询请求。这种模块化设计使得Druid能够灵活部署,并轻松应对数据量的增长。
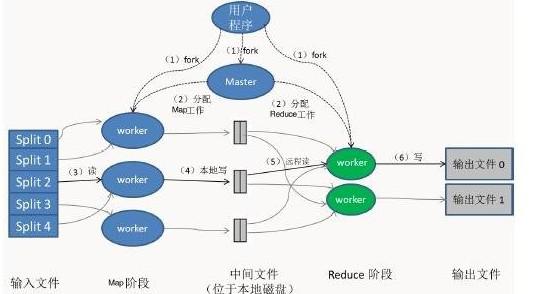
在数据处理方面,Druid支持从多种数据源实时摄取数据,如Kafka、Amazon Kinesis等流式平台,同时也支持批处理方式导入历史数据。数据在摄取过程中会进行预聚合和索引,并采用列式存储格式,极大地优化了查询性能。Druid的查询引擎支持低延迟的OLAP查询,能够快速完成复杂的数据聚合、过滤和分组操作,通常能在亚秒级内返回结果。
Druid的应用场景非常广泛。在互联网行业,它常用于用户行为分析、广告效果实时监控和A/B测试;在物联网领域,可用于设备状态监控和时序数据分析;在金融行业,则适用于实时风险控制和交易监控。许多知名公司,如阿里巴巴、Netflix和Airbnb,都在其数据架构中部署了Druid,以应对高并发、低延迟的实时分析需求。
Druid作为一个高性能的实时分析数据库,以其卓越的查询速度、可扩展性和可靠性,成为了大数据生态系统中不可或缺的一环。随着实时数据处理需求的不断增长,Druid将继续演进,为更多企业提供强大的数据处理服务,帮助他们在数据洪流中捕捉价值,驱动智能决策。
如若转载,请注明出处:http://www.honpuiot.com/product/14.html
更新时间:2026-06-19 04:03:17