云计算数据处理服务 定义、核心能力与价值

云计算数据处理服务是指利用云平台提供的按需、可扩展的计算资源、存储能力和分析工具,对海量、多样化、快速变化的数据进行采集、存储、处理、分析和可视化的综合服务。它将传统数据处理的复杂基础设施(如服务器集群、存储阵列、数据库软件)转变为在互联网上可随时获取的服务,使用户能够专注于数据本身的价值挖掘,而无需管理底层硬件和基础软件的复杂性。
核心服务模式与组件
云计算数据处理服务通常遵循云计算的三种主要服务模式:
- 基础设施即服务 (IaaS):提供虚拟化的计算资源(如虚拟机)、存储和网络。用户可以在这些基础资源上自行部署和运行数据处理软件,例如在云服务器上搭建Hadoop或Spark集群。这提供了最大的灵活性,但也需要较高的技术管理能力。
- 平台即服务 (PaaS):提供集成的数据处理平台和开发环境。用户直接使用云服务商提供的数据库、大数据分析引擎、流处理服务等,无需关心底层操作系统的维护。例如,使用AWS的Amazon Redshift(数据仓库服务)或Google BigQuery进行交互式查询分析。这是当前主流的数据处理服务模式。
- 软件即服务 (SaaS):提供直接可用的、基于云端的数据处理应用。用户通过网页或API即可使用数据分析、商业智能(BI)或数据可视化功能,例如使用Tableau Online或Microsoft Power BI服务。
典型的数据处理服务组件包括:
- 数据存储服务:对象存储(如AWS S3)、云数据库(SQL与NoSQL)、数据湖存储。
- 数据处理引擎:批量处理服务(如AWS EMR)、流处理服务(如Azure Stream Analytics)、交互式查询引擎。
- 数据集成与编排工具:用于数据迁移、ETL(提取、转换、加载)和任务调度的服务。
- 分析与机器学习服务:预构建的机器学习模型、AI工具和商业智能仪表板生成服务。
核心优势与价值
- 弹性与可扩展性:这是云计算数据处理最显著的优势。用户可以根据数据量的波动和计算需求的峰值,即时扩展或缩减资源,实现近乎无限的水平扩展能力,并只为实际使用的资源付费。这完美应对了大数据时代数据量不可预测的增长。
- 成本效益:采用按使用量付费的模式,避免了前期高昂的硬件采购和数据中心建设成本。云服务商负责硬件的维护、升级和电力成本,将资本性支出(CapEx)转化为运营性支出(OpEx)。
- 敏捷性与创新速度:企业可以在几分钟内部署一个完整的数据处理环境,快速启动数据分析项目、试验新算法或构建数据驱动型应用,极大地缩短了从数据到洞察的时间周期。
- 丰富的服务生态与集成:主要云平台(如AWS、Azure、Google Cloud)提供了从数据摄入到智能分析的全栈式、相互集成的服务套件,并持续集成最新的技术(如AI/ML),降低了技术选型和集成的复杂度。
- 高可用性与安全性:领先的云服务商在全球范围建设了多个可用区,提供了内置的数据冗余、备份和灾难恢复能力。它们投入巨资构建了多层次的安全合规体系,其安全能力往往超过单个企业自建的数据中心。
典型应用场景
- 大数据分析:分析网站日志、传感器数据、社交媒体流,以获取用户行为洞察或运营优化建议。
- 数据仓库现代化:将传统的本地数据仓库迁移至云端,构建更灵活、成本更低的云原生数据仓库。
- 实时数据处理:处理IoT设备数据流,实现实时监控、预警和动态响应。
- 人工智能与机器学习:利用云上的GPU算力和托管式ML服务,训练和部署预测模型、图像识别或自然语言处理应用。
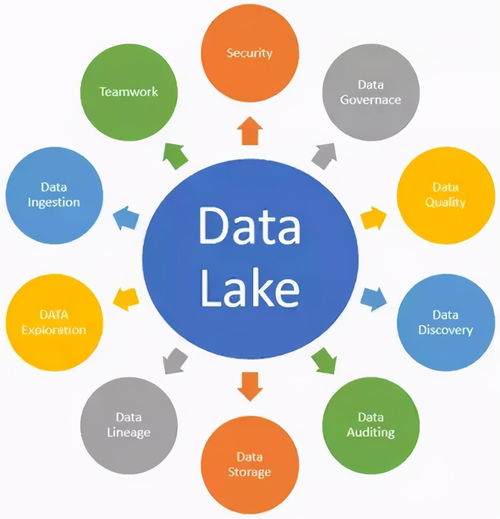
- 数据湖构建:在低成本的对象存储上集中存储企业的所有原始数据,作为统一的分析数据源。
挑战与考量
尽管优势显著,企业在采用云计算数据处理服务时也需考虑:
- 数据安全与合规:确保数据(尤其是敏感数据)在传输、静态存储和处理过程中符合行业法规和公司政策。
- 数据迁移与网络成本:将海量历史数据迁移上云可能耗时且产生网络传输费用。
- 供应商锁定风险:深度依赖某一云平台的服务和API,可能导致未来迁移到其他平台的成本高昂。
- 持续的成本优化:需要精细监控资源使用情况,通过调整实例类型、使用预留实例、优化存储层级等手段控制成本。
总而言之,云计算数据处理服务通过将强大的数据处理能力民主化、服务化,已成为现代企业数字化转型和数据驱动决策的核心引擎。它正持续推动着从IT基础设施到业务创新模式的深刻变革。
如若转载,请注明出处:http://www.honpuiot.com/product/17.html
更新时间:2026-06-19 05:04:43