深入浅出数据流水线管理(上) 数据处理服务
在数据驱动决策的时代,高效、可靠的数据处理能力是企业的核心资产。数据流水线,作为连接原始数据与业务洞察的“数据高速公路”,其管理与优化至关重要。本系列文章将分上下两篇,为您深入浅出地解析数据流水线管理的核心要义。上篇,我们将聚焦于数据流水线的基石——数据处理服务。
一、什么是数据流水线与数据处理服务?
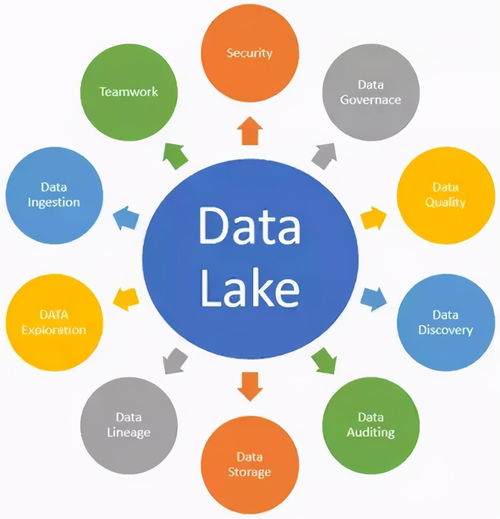
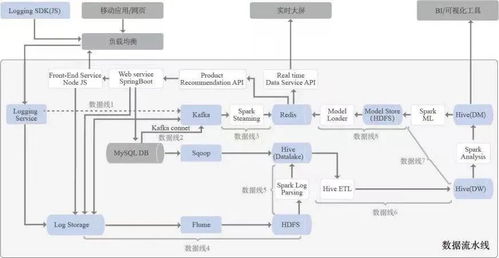
数据流水线是一个自动化的流程,它将数据从源头(如数据库、日志文件、传感器)采集、传输、转换、加工,最终加载到目标系统(如数据仓库、分析平台或应用程序)中,以供存储、分析和使用。整个过程如同一条精心设计的工业流水线,确保数据在各个环节有序、高效地流动。
而数据处理服务,则是这条流水线上执行核心“加工”任务的“工作站”或“服务单元”。它负责对原始数据进行清洗、转换、聚合、丰富等操作,将杂乱无章的原始数据转化为格式统一、质量可信、适合下游使用的结构化信息。
二、数据处理服务的核心价值
- 质量提升:通过清洗(去重、纠错、补全)、验证规则等,消除数据中的“噪声”与不一致性,保障数据可信度。
- 价值提炼:将原始数据转换为蕴含业务意义的指标、特征或聚合结果(如每日销售额、用户活跃度),直接服务于分析与决策。
- 效率优化:自动化处理替代人工操作,实现大规模数据的快速、批量化处理,释放人力并减少错误。
- 标准化与集成:将来自不同源头、格式各异的数据,转换为统一的模型和格式,打破数据孤岛,实现数据融合。
三、数据处理服务的关键组件与模式
一个健壮的数据处理服务通常包含以下关键部分:
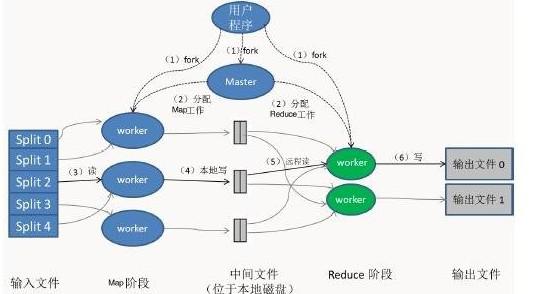
- 处理引擎:执行计算的核心,如Apache Spark(擅长大规模批处理与流处理)、Apache Flink(以低延迟流处理见长)、以及传统的MapReduce或各类云服务(如AWS Glue、Azure Data Factory)。
- 计算模式:
- 批处理:定期(如每小时、每天)对累积的批量数据进行处理,适合对时效性要求不高的报表、历史分析等场景。
- 流处理:对连续产生的数据流进行实时或近实时处理,适用于监控、实时推荐、欺诈检测等需要快速响应的场景。
- Lambda/Kappa架构:结合批处理与流处理优势的混合架构,兼顾数据的准确性与时效性。
- 任务调度与编排:协调数据处理任务间的依赖关系与执行顺序,确保流水线顺畅运行(常用工具如Apache Airflow、Luigi、云托管调度服务)。
- 监控与治理:对数据处理作业的运行状态、性能指标(处理时长、资源消耗)、数据质量进行实时监控与告警,确保服务稳定可靠。
四、构建高效数据处理服务的实践要点
- 明确目标,始于设计:在设计之初,必须清晰定义处理后的数据需要满足哪些业务需求(输出什么指标?谁使用?时效性要求?),以此驱动技术选型与架构设计。
- 模块化与可复用:将处理逻辑分解为独立、功能单一的任务或函数模块。这样不仅便于开发、测试和维护,也提升了代码的可复用性,避免“烟囱式”开发。
- 鲁棒性与容错:数据处理服务必须能够优雅地处理各种异常情况,如数据源暂时不可用、数据格式意外变化、计算资源不足等。设计时应考虑重试机制、死信队列、检查点等容错策略。
- 可观测性贯穿始终:建立完善的日志、指标和追踪体系。不仅要监控作业是否成功,更要洞察其性能瓶颈、资源利用效率和数据质量变化趋势,为持续优化提供依据。
- 拥抱自动化与DevOps:将数据处理服务的开发、测试、部署、监控纳入CI/CD(持续集成/持续部署)流程,实现快速迭代和可靠发布。
###
数据处理服务是数据流水线中创造价值的核心环节。它不仅是技术的实现,更是业务逻辑与数据技术的交汇点。一个设计精良、运行稳健的数据处理服务,能够为企业的数据资产注入活力,为上层的数据分析、机器学习与智能应用奠定坚实可靠的基础。
在下篇中,我们将把视角从单个的“服务”扩展到整条“流水线”,深入探讨数据流水线的全生命周期管理、编排、监控与治理,敬请期待。
如若转载,请注明出处:http://www.honpuiot.com/product/1.html
更新时间:2026-06-19 06:53:23