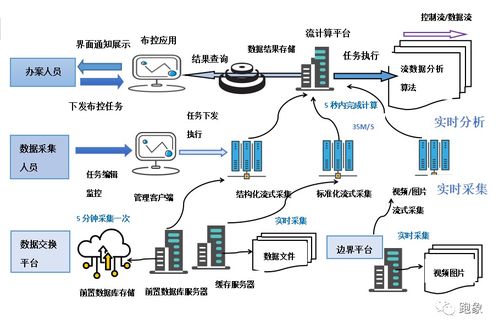
流批一体 实时数据处理场景化典型应用实例与干货分享
随着大数据技术进入深水区,企业对数据处理的需求已从单一的离线分析,演变为对实时性、准确性与成本效率的综合追求。在此背景下,“流批一体”架构应运而生,成为新一代数据处理服务的核心范式。它通过统一的数据处理引擎和存储层,无缝衔接实时流处理与离线批处理,极大地简化了技术栈,降低了运维复杂度。本文将通过几个典型场景化应用实例,深入剖析其价值,并分享构建高效数据处理服务的实战干货。
一、典型应用场景实例
- 电商实时大屏与历史报表分析
- 场景痛点:传统模式下,实时交易数据通过Flink等流引擎计算GMV、UV等指标展示在大屏上;而每日的深度经营分析报表(如用户复购率、品类销售趋势)则依赖T+1的离线Hive/Spark任务生成。两套系统导致数据口径不一致、研发维护成本双高。
- 流批一体方案:采用Apache Flink或Apache Spark Structured Streaming作为统一计算引擎,搭配Iceberg、Hudi或Delta Lake等开源数据湖表格式作为统一存储层。所有交易数据实时写入数据湖表。
- 实时路径:Flink直接消费数据湖表的变更日志(如CDC流),进行低延迟聚合,结果输出至OLAP数据库(如ClickHouse)供实时大屏查询。
- 批处理路径:在每日固定时间点,Spark或Flink Batch模式基于同一张数据湖表,运行更复杂的ETL和关联查询,生成T+1的精准报表。
- 核心价值:一份存储,两种计算模式,保障了从“秒级”到“天级”所有数据应用口径的绝对一致,节省了大量数据核对与清洗成本。
- 金融风控与合规审计
- 场景痛点:反欺诈系统需对每笔交易进行毫秒级实时规则与模型判断;而监管报送和事后审计则需要回溯查询任意时间段的全量明细数据。系统割裂易造成风控规则在实时与批量环境下表现不一。
- 流批一体方案:以实时事件流(如交易日志)作为唯一数据源。
- 实时路径:数据流经风控规则引擎进行实时扫描与决策,风险事件实时告警。
- 批处理路径:同一数据流同时被持久化到具备事务能力的数据湖存储中,形成不可篡改的审计溯源基线。合规部门可直接使用SQL对历史全量数据进行回溯分析与复杂关联查询,生成监管报表。风控模型的迭代训练,也可直接基于数据湖中的高质量历史数据进行特征提取。
- 核心价值:实现了风控逻辑的“一次开发,处处运行”,确保了审计数据的完整性与可追溯性,满足了金融行业严苛的合规要求。
- 物联网设备状态监控与预测性维护
- 场景痛点:数十万设备的传感器数据持续上报,需要实时监控异常状态并告警;为了优化维护策略,需要长期历史数据来训练设备故障预测模型。
- 流批一体方案:设备遥测数据接入Kafka等消息队列。
- 实时路径:Flink作业实时消费数据,计算设备当前健康指标(如温度阈值、振动幅度),一旦发现异常立即触发工单。
- 批处理路径:所有原始数据通过流作业同步至数据湖,作为“数据仓库的ODS层”。数据科学家定期从数据湖中抽取数月甚至数年的数据,进行特征工程,训练和优化预测性维护模型。训练好的模型又可发布回流处理管道,用于实时预测。
- 核心价值:打通了从实时响应到长期优化的闭环,让数据在“热”(实时处理)与“冷”(深度分析)之间自由流动,最大化数据价值。
二、构建流批一体数据处理服务的核心干货
- 架构选型:统一是核心
- 计算引擎:优先考虑Apache Flink,其DataStream API和Table API/SQL天然支持流批统一。Apache Spark Structured Streaming也是成熟选择,其“微批”模型在吞吐量上常有优势。
- 存储层:这是流批一体的基石。强烈推荐采用数据湖表格式(Table Format),如 Apache Iceberg、Apache Hudi 或 Delta Lake。它们提供了ACID事务、时间旅行(Time Travel)、 schema演进等关键特性,使得同一份数据能被流任务增量读取、批任务全量扫描,且保证一致性。
- 数据通道:使用Apache Kafka或Pulsar作为实时数据总线,确保数据的可靠传输与缓冲。
- 数据建模:维度建模的演进
- 在流批一体架构下,经典的维度建模依然适用,但思维需从“批量调度”转向“持续生成”。
- 建议构建“分层一体化”模型:将数据湖作为统一的ODS/DWD层,原始和轻度聚合的数据在此沉淀。上层的DWS/ADS层,既可以通过流作业持续物化视图(用于实时查询),也可以通过批作业周期性生成(用于复杂报表)。关键在于使用统一的元数据管理(如Hive Metastore或项目自带的Catalog)来定义这些表。
- 开发与运维:关键实践
- SQL优先:尽可能使用Flink/Spark SQL进行开发,这能最大程度地统一流批作业的业务逻辑,降低开发维护门槛。
- 统一的作业管理与调度:采用Apache DolphinScheduler、Airflow或云厂商的托管服务,将流任务(常驻)和批任务(周期)在同一平台进行部署、监控与告警管理。
- 关注数据时效性与正确性的平衡:流处理追求低延迟,可能需处理乱序数据。合理设置水位线(Watermark)和利用存储层的事务特性,在“延迟”和“准确”间找到业务平衡点。对于要求精确一次的场合,务必启用检查点(Checkpoint)和端到端精确一次语义。
- 成本优化:利用数据湖的存储分层功能(如将历史冷数据自动转储至对象存储),并合理设计批处理作业的扫描分区,避免全表扫描,控制计算成本。
###
流批一体并非一个全新的技术,而是一种架构思想的进化。它直面了企业数据链路复杂、冗余、不一致的核心痛点。通过上述场景实例可以看出,其价值在于用一套简洁的技术体系,同时满足实时业务响应与深度数据分析的需求,让数据团队能更专注于业务逻辑本身,而非底层架构的缝合。随着数据湖技术的日益成熟,流批一体已成为构建现代化、高效率数据处理服务的必然选择。企业在规划自身数据平台时,应将其作为核心目标进行考量与迭代。
如若转载,请注明出处:http://www.honpuiot.com/product/7.html
更新时间:2026-06-19 15:38:54